本文主要介绍sqlserver查询去除重复数据的实现,具有很好的参考价值,希望对大家有所帮助。和边肖一起来看看
说明:
只要数据表的“列名”数据相同,就意味着是两个重复的数据(ID是自动增长的数据表的主键)。
推荐方法1
-方法1
从表名A中选择*不存在(从表名中选择1,其中列名=a .列名和IDA。ID)
-方法2
从表名A内部联接中选择A.*(从表名组中选择min(ID) ID,按列名选择列名)b对A .列名=B .列名和a. id=B。
-方法3
从表名中选择*其中标识=(从表名中选择最小标识,其中列名=列名)
补充:SQL SERVER 查询去重 PARTITION BY
rownumber() over(按col1分区,按col2排序)
重复数据消除的方法非常好,在此记录:
row_number() OVER(按列1分区,按列2排序)
指在分组内按COL1分组,按COL2排序,该函数计算的值是指每组内排序后的序号(组内连续唯一)。
直接查询,很多都是一样的,但我只想取创建日期时间最长的那个
从框中选择从标识、子实例、库、创建日期、同步日期、相关关键字
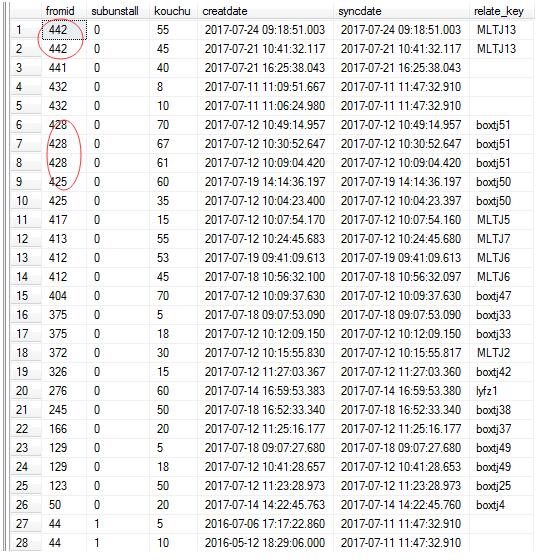
使用
根据创建DESC的id ORDER进行分区
根据中的fromid分组,根据creatdate组排序。
其中RN=1;取第一个数据
选择* from(从id中选择,sub unmount,kouchu,creatdate,syncdate,relay _ key,tansha SEO row _ number()over(按id从顺序分区,由creat date desc)rn from box count _ froms _ open)t其中rn=1;
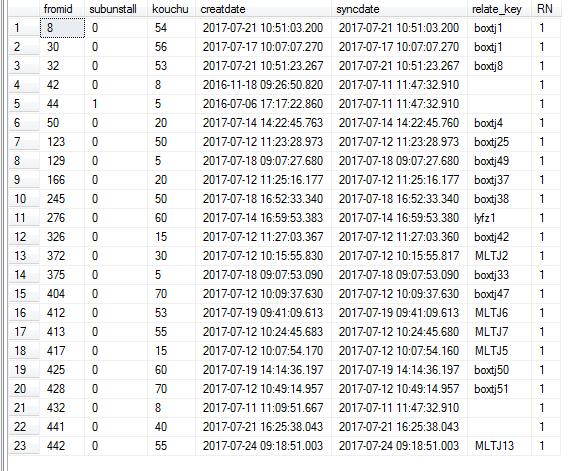
以上是我的亲身经历,希望能给大家一个参考,也希望大家多多支持剧本屋。如果有任何错误或不足,请随时给我们建议。
