本文主要介绍postgresql数据合并,以及将多个数据合并为一个的操作,有很好的参考价值,希望对大家有所帮助。来和边肖一起看看。
对于主表中的一条记录,它对应于明细表中的96条数据,每条数据相隔15分钟。明细中没有96条数据对应主表中的一个日期trade_date,每个明细中都有一个start_time字段,即明细中每96条数据中的第一条数据为00336000。
第二项是00:15,第三项是00:30,以此类推,直到2:45。现在,日程中的96项数据应该合并成24项,即第一项的start_time为00:00,第二项为01336000,第三项为02:00。
SQL : select max(de . bid _ num)report _ num,concat(to _ char(to _ TIMESTAMP)(concat(ru . trade _ date,",de.start_time),' YYYYY-MM-DD hh 24: mI ')33603360 TIMESTAMP NORTH ZONE,' HH24 ',' :00 ')DD from quote _ trade _ rule ru LEft JOICE quote _ trade _ rule _ detail de on ru . trade _ rule _ id=de . trade _ rule _ id
在哪里
1=1
AND ru . market _ id=' a 29 c 81 ed-2 BAF-4c 42-881 a-f1 e 64 a 41 E1 b 0 '
AND to_char(ru.trade_date,' YYYY-MM-DD')='2018-10-17 '
和ru.rule_type='2' GROUP BY dd,trade_date ORDER BY dd,trade_date
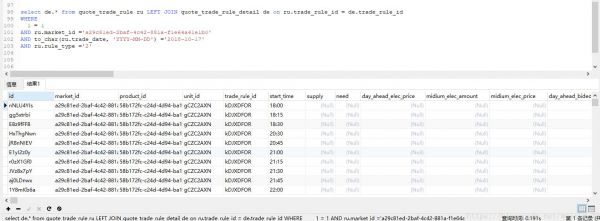
将10个主表数据对应的960个明细数据合并成以下24个数据:
补充:Postgresql中执行计划的合并连接
合并连接
一般来说,散列连接的效果比合并连接好。但是,如果源数据上有索引或者结果已经排序,那么在排序合并联接时就不需要排序,那么合并联接的性能会比散列联接好。
在下面的例子中,人的id字段和德唐山百度优化pt01的depto字段都有索引,从索引中扫描出来的数据已经排序,可以直接取Merge Join:
high go=# explain select people . id from people,dept 01 where people . id=dept 01 . dept no;
查询计划
-
合并连接(成本=0.86.64873.59行=1048576宽=4)
merge cond :(people . id=dept 01 . dept no)
-仅索引扫描使用人员对人员(成本=0.44.303935.44行=10000000宽=4)
-在dept01上使用idx_deptno仅索引扫描(成本=0.42.51764.54行=1048576宽=2)
(4行记录)
如果删除dept01上的索引,您会发现dept01首先被排序,然后在执行计划中执行合并连接。示例如下:
high go=# explain select people . id from people,dept 01 where people . id=dept 01 . dept no;
查询计划
-
合并连接(成本=136112.80.154464.29行=1048576宽=4)
merge cond :(people . id=dept 01 . dept no)
-仅索引扫描使用人员对人员(成本=0.44.303935.44行=10000000宽=4)
