近期,自己承担的在其中一个网站百度收录出現了出现异常,借着礼拜天有时间叙述一下全部确诊全过程。关键难题有二点,服务器架构和网站源代码构架造成 的;这篇仅共享服务器架构造成 的百度收录出现异常。
最先,介绍一下自身。自己任职于深圳市某公司,长期性混在于承包方外包服务,大家都知道seo外包企业接的是绝大多数是中小企业网址,这种网址做的关键字通常也仅是改个TDK就进行排行的工作中。
再再加,现阶段绝大多数中小型网站的构架非常简单,开源系统CMS 单一云主机(云虚拟主机) CDN(这還是有点儿运维管理工作能力企业)。由于之上工作经验,造成 自己彻底沒有意识到服务器架构层面也可以出現难题。
一、百度收录出现异常的发觉
从(图1)能够 和显著的看得出,在三月中旬百度收录是偏重一切正常的,难题出現在3.31日-4.25日中间出現了波动,换句话说,这一区段一定是网站出現了难题造成 百度收录出现异常。
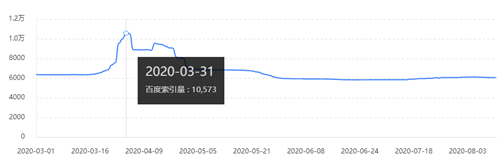
自己刚开始按基本方式 清查,非常是网络服务器系统日志一些主要参数沒有清除留意,以致于造成 了难题发觉,实际以下:
1.1、百度站长工具仿真模拟网络爬虫爬取,一切正常。
1.2、百度搜索引擎网络爬虫爬取总数在提高,偏重一切正常。这里有出现异常,清查伪搜索引擎蜘蛛网络爬虫在抓数据信息,真正百度蜘蛛的确也在提高。
1.3、关键关键字排名波动,但偏重且增长的趋势靠前,现阶段关键长尾词处在前5名,一切正常。
1.4、网络服务器日志分析系统,网络爬虫相匹配的request_uri值(相对性详细地址),暂属一切正常,可以看下面。
1.5、网络服务器系统日志是阿里云服务器的系统日志,http要求,7.18日、7.18日、7.21日及其7.26日出現小总面积网络服务器500浏览不正确;但最多个出現比较有限的時间百度收录出现异常,不会大范畴不百度收录。
在网络服务器浏览日志分析系统中,一般必须留意的项是:网络爬虫爬取時间值,网络爬虫网页页面URL值,网络爬虫在网页页面爬取次序,時间内网络爬虫爬取总数,另一说搜索引擎蜘蛛IP值有权重值高矮之分(自己不确定性,故不参照)
网页页面URL值:一般网络服务器系统日志是相对性详细地址,自己确诊出現的难题取决于忽视host值,真正爬取URL应该是,host request_uri值组成。
网页页面爬取次序:可检测网站结构的爬取状况,大约能够 了解网络爬虫在网页页面中的爬取次序,能够 輔助应用爬虫工具或是开发设计經典网络爬虫(PY,PHP等)的爬取状况做为参照
時间内网络爬虫爬取总数:检测网页页面总产量和时间范围内爬取量的占有率,分辨网址的火爆水平。
